Computer Vision - Proyecto Final: RepNet¶
Por: Eric Aguayo
Introducción¶
- Las acciones repetitivas o ciclicas estan siempre en nuestras actividades diarias
- Evidente en actividades deportivas: crossfit, atletismo, etc..
- Latidos del corazón, respiración, gente bailando, construcción, ciclos planetarios, etc.
- Es preciso reconocer estos patrones y tener un sistema que pueda identificar y contar estos ciclos.
Repeticiones¶
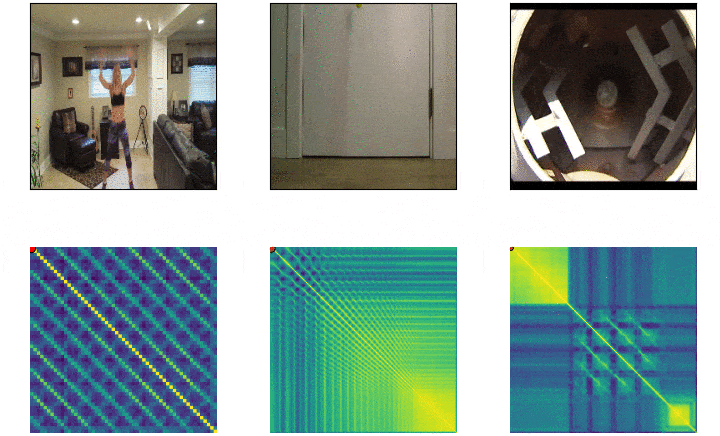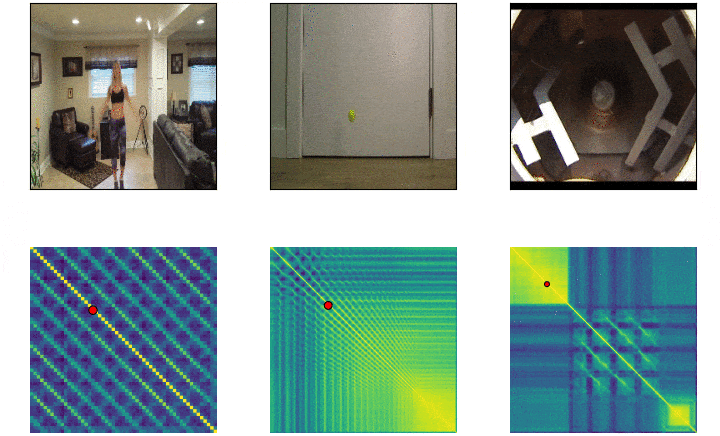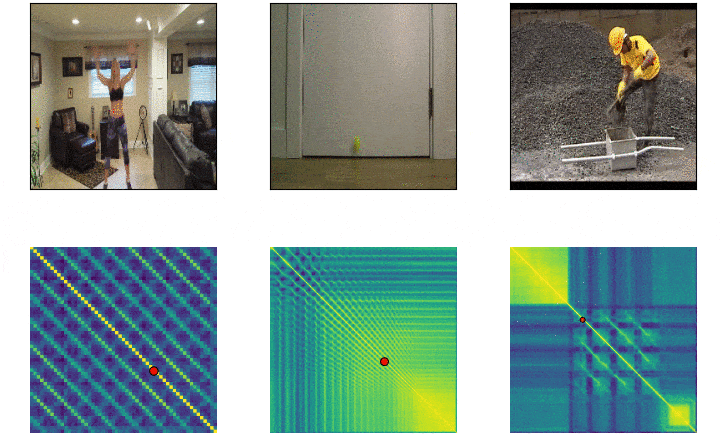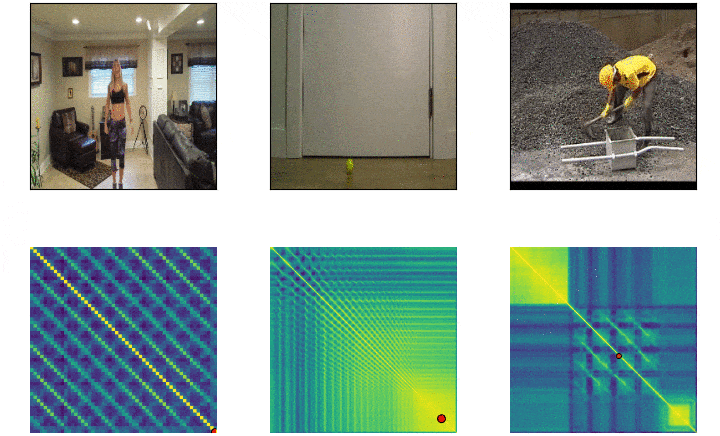
Objetivos¶
- Construir un sistema que detecte si un patrón repetivo tiene ocurrencia
- Si es que hay un patron repetitivo, determinar la longitud del patron y poder contar el número de eventos
Retos/Dificultades¶
- Los patrones repetitivos pueden ser de distinta índole y muy diferentes entre si
- Que exista un movimiento no necesariamente implica que haya una actividad repetitiva
- Los ciclos pueden tener distintas longitudes
- Pelota rebotando - los periodos se acortan en el tiempo
- Actividad deportiva - los periodos se alargan en el tiempo por la fatiga
Acercamiento al problema¶
- Estimar el período con el que una acción se repite en un video -> conteo de repeticiones
Predicciones¶
- Por cada frame:
- Determinar si es que hay una periodicidad -> variable binaria (hay repetición o no)
- Determinar cual es la longitud del período -> permite realizar un conteo
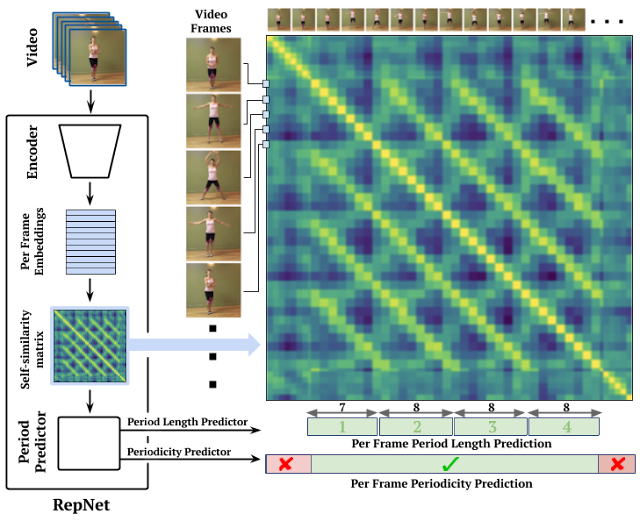
Descripción General de la arquitectura¶
El Dataset (Countix)¶
Datos tabulares en CSV conteniendo ids de videos de youtube y etiquetas
| video_id | class | kinetics_start | kinetics_end | repetition_start | repetition_end | count |
|---|---|---|---|---|---|---|
| D5Ge91h0XZw | battle rope training | 38 | 48 | 38.000000 | 44.633333 | 7 |
Data Sets:¶
- Train: 4412 -> 4103
- Val: 1407 -> 1291
- Test: 2556 -> 2372
Para descarga se utilizó yt-dlp y se hizo un filtrado de videos no válidos o no accesibles
Arquitectura del modelo¶

Video > batches de 64 frames > Encoder > Embeddings > Self-Similarity Matrix > Multihead self-attention Transformer > Period Length Predictor & Periodicity Predictor
Encoder¶
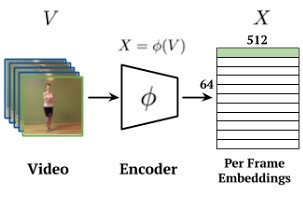
- Extractor de características: Resnet 50 (pretrained weights)
- Embeddings iniciales pasan por una Convolución 3D para extraer características temporales de los vecinos con kernel de 3x3x3
- Reducción de disponibilidad (Max Pooling)
# Encoder
encoder = torch.hub.load("huggingface/pytorch-image-models", model_name)
#...
# Temporal Convolution layers
self.temporal_conv = nn.Sequential(
nn.Conv3d(
in_channels=1024, # From encoder
out_channels=self.temporal_conv_channels,
kernel_size=self.temporal_conv_kernel_size,
padding="same",
dilation=(self.temporal_conv_dilation, 1, 1),
),
nn.BatchNorm3d(self.temporal_conv_channels, eps=0.001),
nn.ReLU(inplace=True),
nn.AdaptiveMaxPool3d((None, 1, 1)),
nn.Flatten(2, 4),
)
Self-similarity Matrix¶
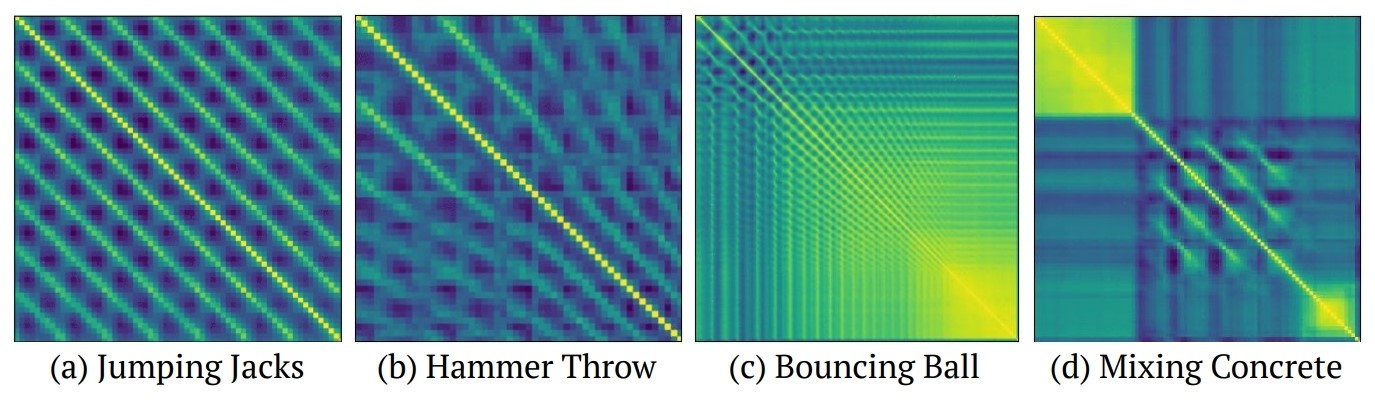
- Negativo de la distancia euclideana $f(a,b)= -||a-b||^2$
- Seguida de una operacion softmax por fila
def get_sims(self, embs, temperature):
# Compute temporal self-similarity matrix
sim_mat = torch.cdist(embs, embs)**2 # N x D x D
sim_mat = -sim_mat / temperature
sim_mat = sim_mat.softmax(dim=-1)
return sim_mat
Predictor¶
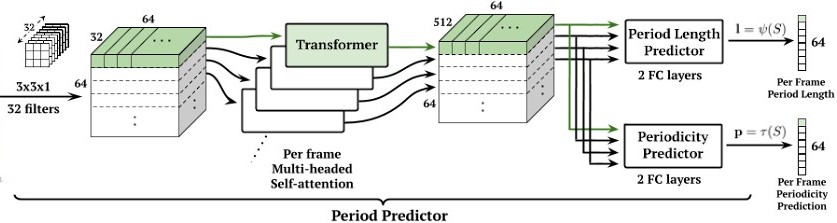
- Conv2D -> Expandir a 32 canales (upsample) con kernels de 3x3. Cada frame corresponde un "slice" de 32x64
- Capa de Transforme que usa atención con múltiples cabezas con embeddings posicionales de tamaño 64 y 4 cabezas con 512 dimensiones (cada cabeza 128 dimensiones). Extrae las propiedades temporales
- Predictores usan la arquitectura de transformer compartida hasta la etapa de clasificación
- $l = \Psi(S)$
- $p = \tau(S)$
# Counting Module (Self-sim > Conv > Transformer > Classifier)
self.conv_3x3_layer = nn.Sequential(
nn.Conv2d(
in_channels=1, # assuming single channel input from self-similarity
out_channels=self.conv_channels,
kernel_size=self.conv_kernel_size,
padding="same",
),
nn.ReLU(inplace=True),
)
class TransformerHead(nn.Module):
class TransformerLayer(nn.Module):
"""A single transformer layer with self-attention and positional encoding."""
def __init__(
self, in_features: int, n_head: int, out_features: int, num_frames: int
):
super().__init__()
self.input_projection = nn.Linear(in_features, out_features)
self.pos_encoding = nn.Parameter(
torch.normal(mean=0, std=0.02, size=(1, num_frames, out_features))
)
self.transformer_layer = nn.TransformerEncoderLayer(
d_model=out_features,
nhead=n_head,
dim_feedforward=out_features,
activation="relu",
layer_norm_eps=1e-6,
batch_first=True,
norm_first=True,
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass, expected input shape: N x C x D."""
x = self.input_projection(x)
x = x + self.pos_encoding
x = self.transformer_layer(x)
return x
def __init__(
self,
in_features: int,
n_head: int,
hidden_features: int,
out_features: int,
num_frames: int,
):
super().__init__()
self.predictor_head = nn.Sequential(
self.TransformerLayer(in_features, n_head, hidden_features, num_frames),
nn.Linear(hidden_features, hidden_features),
nn.ReLU(inplace=True),
nn.Linear(hidden_features, hidden_features),
nn.ReLU(inplace=True),
nn.Linear(hidden_features, out_features),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.predictor_head(x)
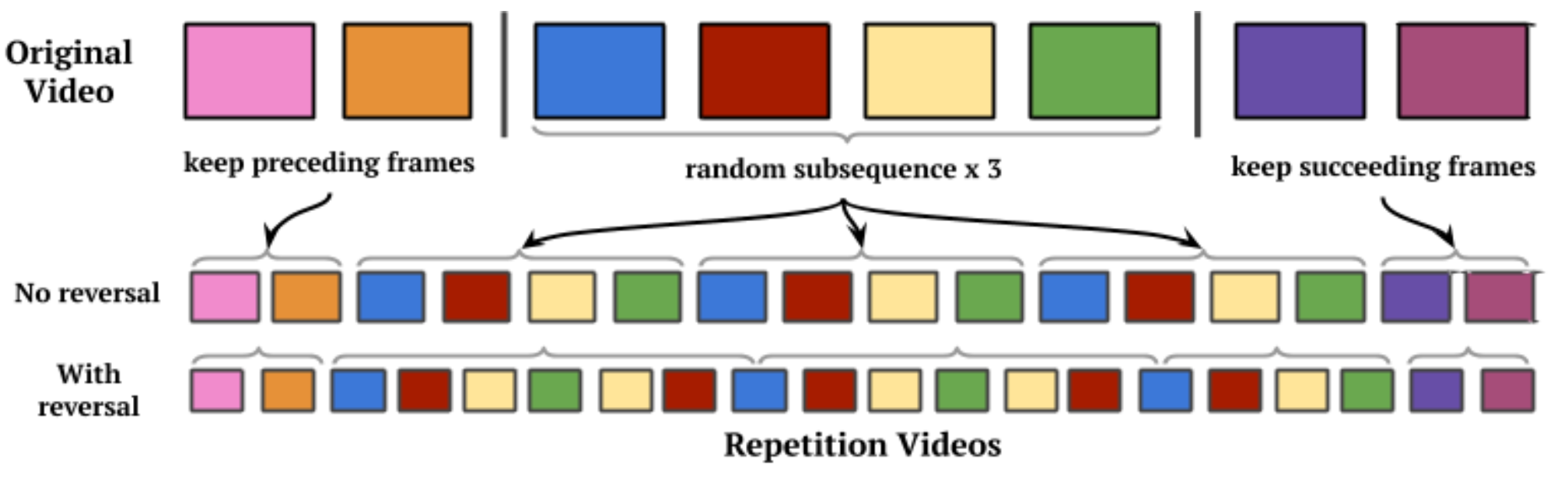
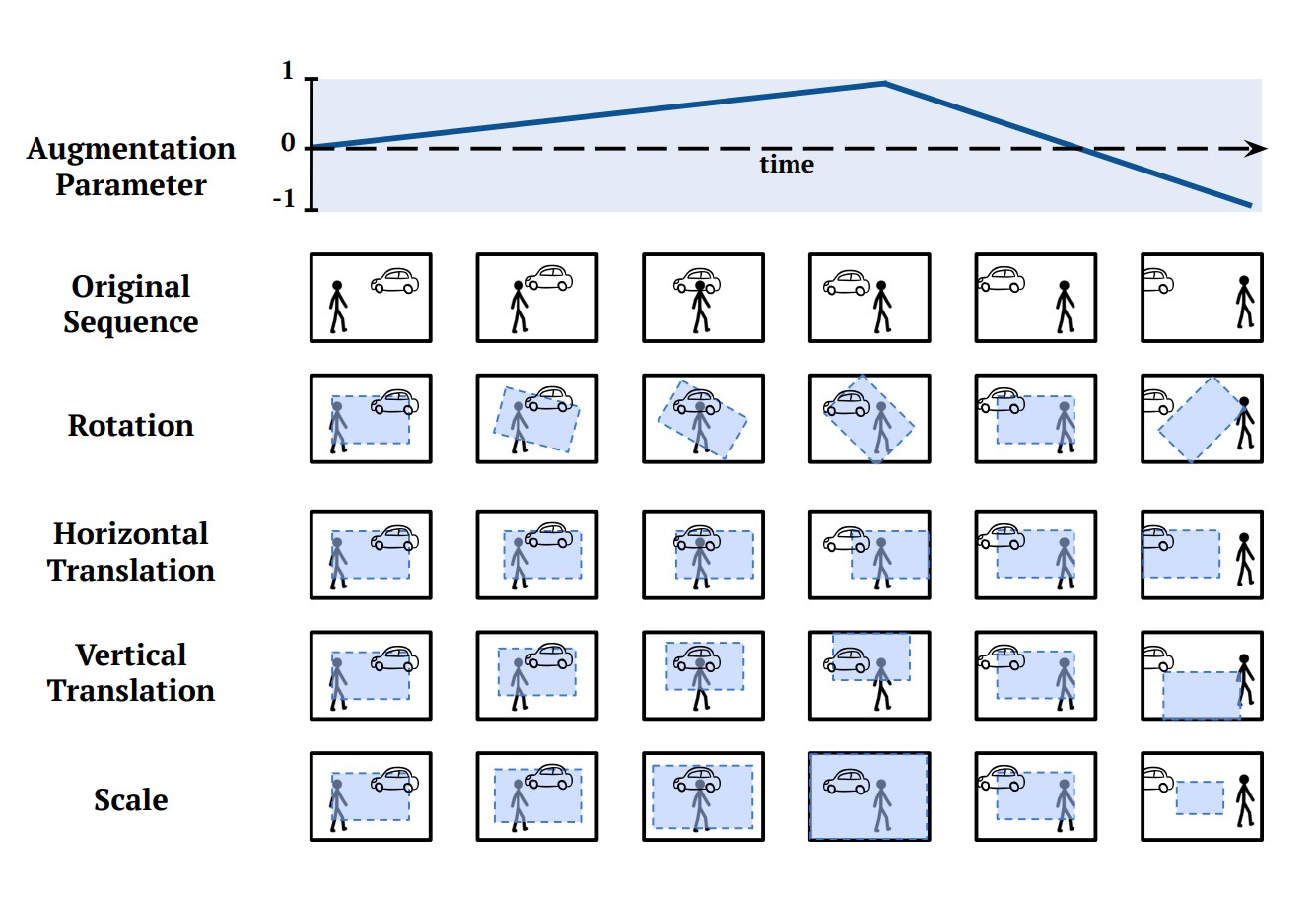
Función de Pérdida¶
- Estimador de periodicidad $\tau$ es una clasificación binaria por lo que se usa binary cross-entropy.
- Estimador de longitud de período $\Psi$ es una clasificación multiclase $\{2,3, ...,\frac{N}{2}\}$ por lo que se usa softmax cross-entropy.
# Forward pass
period_length_pred, periodicity_pred, final_embs = model(frames)
# Calculate losses
# Convert ground truth period lengths to class indices
# Period lengths 2-33 map to class indices 0-31
period_length_classes = torch.clamp(period_length_gt - 2, min=0, max=model.num_frames//2 - 1).long()
# Handle frames with no periodicity (period_length_gt == 0)
non_periodic_mask = (period_length_gt == 0)
period_length_classes[non_periodic_mask] = 0 # Assign to class 0 (period length 2)
# period_length_pred shape: (batch_size, num_frames, num_classes)
# period_length_classes shape: (batch_size, num_frames)
batch_size, num_frames, num_classes = period_length_pred.shape
period_loss = period_length_criterion(
period_length_pred.view(-1, num_classes), # Flatten to (batch_size * num_frames, num_classes)
period_length_classes.view(-1) # Flatten to (batch_size * num_frames,)
)
# Periodicity is a binary classification task (BCE loss)
periodicity_pred_sigmoid = torch.sigmoid(periodicity_pred.squeeze(-1))
periodicity_loss = F.binary_cross_entropy(periodicity_pred_sigmoid, periodicity_gt)
Evaluación¶
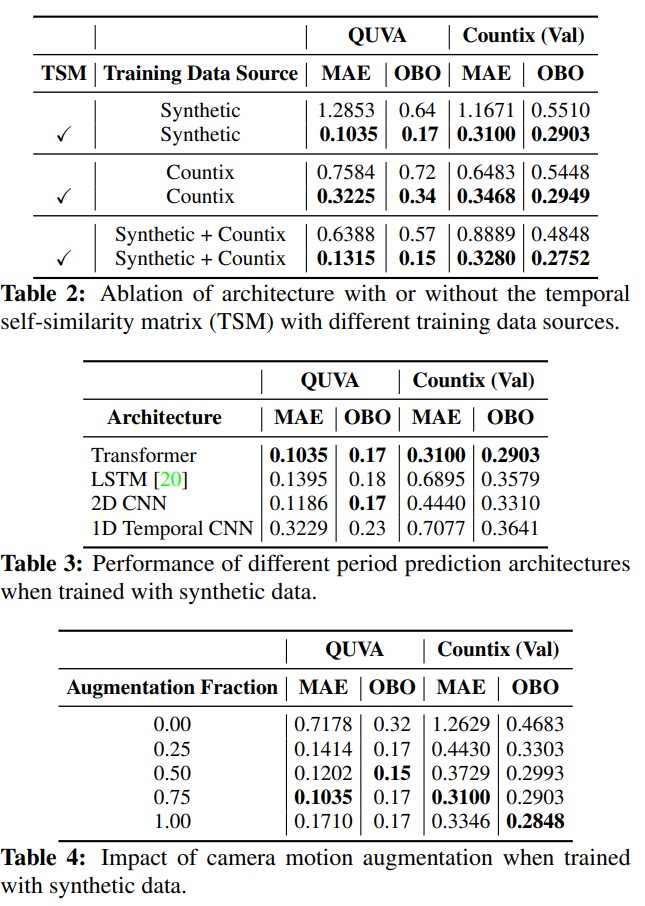
Inferencia¶
- Conteo por frame $\frac{p_i}{l_i}$
- Conteo $\sum_{i=1}^{n} \frac{p_i}{l_i}$
Evaluación multi-velocidad
- Hace inferencia sobre 4 velocidades, usando strides sobre los frames
- Se usa el que tenga el mejor score sobre la predicción del período.
Conclusiones¶
- RepNet es una muestra de que problemas de computer vision que involucran videos con características temporales pueden resolverse con la arquitecura adecuada y las técnicas enseñadas.
- Al trabajar sobre videos, es decir conjuntos de imágenes que tiene una secuencia, es importante la organización para el manejo adecuado de las dimensiones ya que errores en la dimensionalidad pueden ser dificiles de dar seguimiento.
- Las convoluciones en 3D pueden ser muy beneficiosas y útiles para capturar las características temporales de las secuencias de frames que de otra forma no sería posible sobre las imagenes individuales.
- La matriz de auto-similaridad es muy útil para capturar las relaciones entre todos los frames de un batch.
- El uso de mecanismos de atención a través de transformers puede ser muy útil sobre comportamientos complejos en series.secuenciales en los que es relevante la posición.
- Es posible que tener un mejor procesamiento de los datos sinteticos de mejores resultados.
Futuras mejoras potenciales¶
- Volver a entrenar haciendo transfer learning de otro modelo base y descongelar algunas (o todas) capas durante el entrenamiento
- Combinar con object detection para poder realizar repetition counting en multiples objetos en la imagen
- Aplicar normalización adicional a los frames de entrada
- Integrar detección de velocidad de los periodos del video como parte del modelo